
ComfyUI 技術架構解析:Node Graph 背後的設計邏輯
從 Stable Diffusion 到完全可控的 AI 生成工作台
多數人第一次打開 ComfyUI 的反應是:「這什麼?一堆方塊和線?」
然後他們花了十分鐘連接了三四個節點,跑了張圖,突然就明白了。
節點圖(Node Graph)不是一個漂亮的介面裝飾。它是一種看待生成式 AI 的方式——把每個步驟拆解成可獨立設定、可替換、可組合的運算單位。當你能看清楚資料怎麼流動,你就真正掌握了 AI 圖像生成的鑰匙。
這篇文章不是 ComfyUI 新手教學。我假設你已經用過 Stable Diffusion(不管是哪套 GUI),知道什麼是 checkpoint、什麼是 prompt。你想進一步理解:ComfyUI 為什麼這樣設計?它的技術底層是什麼?又能走到多遠?
1. ComfyUI 不是另一個 GUI——它是一種架構思維
1.1 從黑箱到白盒:為什麼節點圖是正確的方向
大多數 Stable Diffusion GUI 把操作封裝成一個一個「功能按鈕」:文生圖、圖生圖、圖片放大……背後藏了多少步運算,你知道嗎?不知道。能不能改?不能。
ComfyUI 換了一個起點:假設你願意看到複雜。
每一個方塊是一個節點(Node),每一條線是一條資料流。節點之間的連接方式決定了整個 pipeline 的行為。這種ComfyUI 節點工作流的設計邏輯,讓你可以讓 CLIP 文字編碼的結果餵給 KSampler,也可以讓 VAE 解碼的 latent 拿去做 ControlNet 增強,甚至可以把同一張雜訊圖分岔給兩個不同的採樣器,最後用 Merge 節點融合結果。
這種自由的代價是:你需要知道自己在做什麼。但換來的,是任何其他 GUI 都做不到的客製化程度。
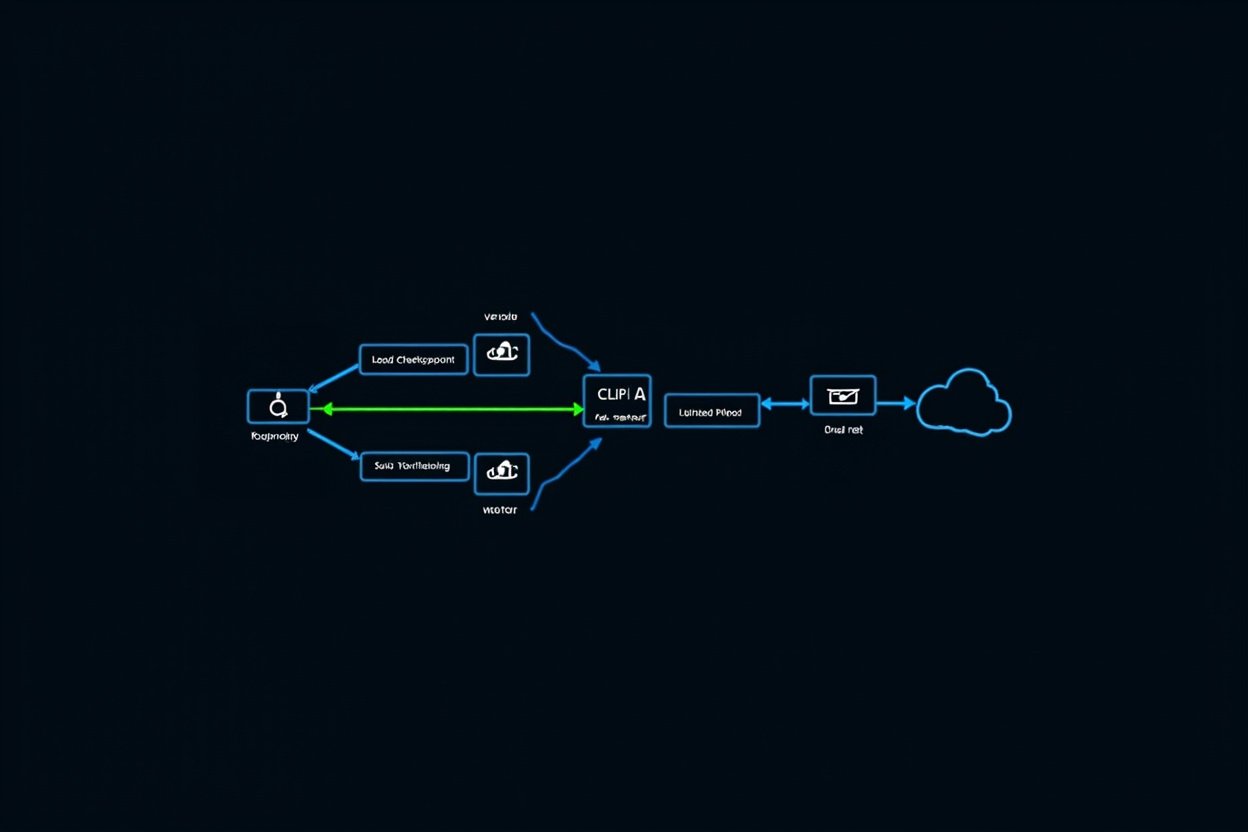
1.2 Node Graph 的資料結構:拓樸排序與上下游依賴
ComfyUI 的工作流本質上是一個有向無環圖(Directed Acyclic Graph, DAG)。每個節點執行後,輸出資料沿連線流向下一個節點。系統在執行前會做一次拓樸排序(Topological Sort),確保每個節點在收到所有上游輸入之前不會執行。
用一個具體例子說明這個設計的威力:
LoadCheckpoint → Clip Text Encode (+ negative) → KSampler → VAE Decode → SaveImage如果我在 Clip Text Encode 跟 KSampler 中間插入一個 ControlNet 節點:
LoadCheckpoint → Clip Text Encode → ControlNet (套用姿態) → KSampler → VAE Decode → SaveImage系統偵測到 ControlNet 節點依賴另一個 LoadCheckpoint 提供的姿態影像,它會自動並行處理 CLIP 文字編碼和 ControlNet 前處理,減少總執行時間。這種隱式的平行化不需要你寫任何程式碼——DAG 結構讓系統自然找出最佳執行順序。
節點之間的連線不只傳遞影像資料。CLIP 文字編碼輸出的是一個包含文字特徵的 embedding 向量,KSampler 接收後執行擴散去噪,VAE Decode 接收的是 latent space 中的雜訊張量。不同類型的資料不能隨意連接,ComfyUI 的型別檢查會阻止無效連線——這是另一個被低估的安全機制。
1.3 與其他 SD GUI 的底層差異
如果你從 Automatic1111(以下簡稱 A1111)或 Forge WebUI 過來,底層差異可能比你想像的大:
Automatic1111 是以 Gradio 為框架的單體應用。核心 Stable Diffusion 邏輯與 Web UI 深度耦合,操作被包裝成 API endpoints,但你沒有辦法在 A1111 裡把「文字編碼→去噪→解碼」中間任何一步置換成自訂節點。想加 ControlNet?裝外掛。想改採樣器的內部參數?改設定檔或等作者更新。
Forge WebUI 基於 A1111 架構改造,號稱比 A1111 快 75%(特定場景下,2024 年 2 月的 YouTube 測試)。ControlNet 場景下速度優勢尤其明顯,而且整合了原本需要外掛的功能,省 VRAM。但本質上仍是同一套封裝邏輯——你不是在使用一個開放的執行環境,而是在操作一個包裝好的功能面板。
ComfyUI 的底層是真正的節點執行引擎。每個節點是一個 Python class,繼承統一介面,輸入輸出規格一致。沒有任何功能被「焊死」——你隨時可以新增一個節點、替換一個節點、組合出前所未有的工作流。代價是:設定與除錯需要更多技術知識,錯誤訊息有時令人費解。
2025 年中旬的社群共識是:若只需要快速比較 checkpoint 或 LoRA 效果,Forge 最方便;若要高度客製的工作流或串接多個 ControlNet,ComfyUI 是唯一選擇。
2. 核心節點詳解:SD 生成流程的每一步都在做什麼
2.1 Checkpoint Loader:模型如何載入、VAE/CLIP/UNet 的角色分工
當你拖入一個 Checkpoint Loader 節點,按下執行,ComfyUI 在背景做了三件事:
CLIP 文字編碼器——將你的 prompt 文字轉成高維向量空間中的表達。CLIP(Contrastive Language-Image Pre-training)是 OpenAI 訓練的一個雙塔模型,學會了文字與影像的對應關係。
UNet 噪聲預測器——這是 Stable Diffusion 的核心。UNet 接收當前 latent 的噪聲狀態 + timestep + 文字 embedding,輸出「這張圖應該往哪個方向去噪」的預測。如何運用這個殘差來更新 latent,就是 KSampler 採樣器的工作。
VAE(Variational Autoencoder)——負責在 pixel space 和 latent space 之間來回轉換。Encoder 將輸入圖像(或來自 KSampler 的 latent)壓縮到 latent space;Decoder 將完成去噪的 latent 還原成可視圖像。VAE 的品質直接決定輸出圖像的銳利度與文字對齊程度。
Checkpoint 檔案(.safetensors)本質上是這三個組件的重量級打包。以 SDXL 為例,整個模型下來 6~7GB,CLIP text encoder 約 1.2GB,UNet 約 4GB,VAE 約 320MB。ComfyUI 的模型管理讓你可以獨立載入任何一個組件——例如換一個更好的 VAE,不動 UNet。
2.2 Clip Text Encode:Prompt 怎麼變成向量、為什麼負向提示詞有效
Prompt 進入 CLIP encoder 後,文字被分詞(tokenize)、轉成 embedding、經過 transformer 架構的多層注意力處理,最終輸出一個高維向量(SDXL 的 embedding 維度是 1280)。這個向量在 KSampler 裡的 cross-attention 層會反覆被查詢——UNet 在每個去噪 step 都會問:「目前這張圖的向量距離我的 prompt 向量有多遠?」
負向提示詞(negative prompt)為什麼有效?因為 CLIP 學到的是「文字-圖像」的對應關係。若你告訴編碼器「不要有手指變形」,它會把這個概念編碼成向量,並在每個 step 對 UNet 施壓:「這裡的向量方向不對,往遠離『手指變形』的方向移動。」這是一種隱式條件約束,不是遮罩或刪除,而是向量空間中的方向性排斥。
在 ComfyUI 中,你可以對正向和負向 prompt 分別做不同的增強設定——不同的 weight(權重)、不同的 end Step(什麼時候停止影響)。
2.3 KSampler:採樣器的數學原理(DDPM vs DDIM vs Euler)
KSampler 是 ComfyUI 工作流的心臟,也是最需要數學理解的環節。
DDPM(Denoising Diffusion Probabilistic Model)是所有 Stable Diffusion 的數學基礎。Forward Process 將乾淨圖片逐步加入 Gaussian 噪聲,經過 T 步(通常 1000 步)後變成純雜訊。Reverse Process 訓練一個神經網路(UNet)學習如何從噪聲中恢復信號。DDPM 的問題是:極慢。50~1000 步才能產生好結果,在消費級 GPU 上不實用。
DDIM(Denoising Diffusion Implicit Models)將 DDPM 的隨機馬可夫過程重新解釋為一個確定性的隱馬可夫模型。DDIM 可用 20~50 步達到接近 DDPM 的品質。當你需要確定性輸出(每次相同 seed + 相同參數得到相同結果)時,DDIM 是首選。
Euler 與 Euler A將去噪過程建模為常微分方程(ODE),用數值方法離散求解。Euler 方法把「複雜的非線性去噪過程」用一連串簡單的線性近似來逼近,每個 step 的計算量比 DDPM 小很多,速度因此更快。Euler a(Karras 變體)使用非線性 noise schedule——在前期給更大步幅讓圖像快速收斂,在後期用更小步幅精細調整細節。
2025 年社群的主流選擇:DPM++ 2M Karras 與 Euler a 並列最推薦組合。若需要確定性重現,用 DDIM。
2.4 VAE Decode/Encode:潛空間到底是什麼、為什麼在 Latent 空間操作
「Latent Space」是理解 Stable Diffusion 最關鍵的概念。Latent Diffusion Model(LDM)(Rombach et al., 2022)的核心創新是:先用 VAE Encoder 把圖像壓縮進一個低維「潛空間」,在潛空間做擴散運算,最後用 VAE Decoder 還原。

壓縮比約 8 倍:512×512 的圖像 → 64×64 的 latent 表示。空間維度 8× 縮減,讓計算量減少了約 98%。
VAE Decode 做的事情是:接收 KSampler 處理完的「接近乾淨」的 latent 張量,用 decoder 網路重建為 pixel space 圖像。不同版本 VAE 的 decoder 品質差異巨大,這就是為什麼 VAE 是一個可以獨立替換的組件。
在 ComfyUI 中,你可以明確地把 VAE Encode 和 VAE Decode 分開使用——Encode 用來把一張已存在的圖像帶入工作流的 latent space,Decode 用來把去噪結果輸出為真正可見的圖片。
3. 擴充機制:Custom Node 與 API 的力量
3.1 如何用 Python 寫一個自己的節點
ComfyUI 節點系統的優雅之處在於:門檻極低,但天花板極高。透過 ComfyUI 自訂節點(Custom Node)機制,任何會寫 Python 的開發者都能為工作流新增功能。
class MyCustomNode:
@classmethod
def INPUT_TYPES(s):
return {
"required": {
"image": ("IMAGE",),
"strength": ("FLOAT", {"default": 1.0, "min": 0.0, "max": 10.0}),
},
}
RETURN_TYPES = ("IMAGE",)
FUNCTION = "process"
CATEGORY = "custom/images"
def process(self, image, strength):
return (modified_image,)INPUT_TYPES 定義了節點接受什麼資料(型別、預設值、範圍約束),RETURN_TYPES 定義輸出,FUNCTION 是實際運算的本體。ComfyUI 的節點系統自動處理序列化、使用者介面生成、以及與其他節點的連線驗證——你只需要專注在商業邏輯。
3.2 熱門 Custom Node 生態(ControlNet、IP-Adapter、ReActor)
ControlNet 系列讓你用外部條件(姿態、骨骼、深度圖、分割圖)來控制 Stable Diffusion 的生成方向。ComfyUI 的 ControlNet 整合非常完整——你可以同時疊加多個 ControlNet 條件,各自設定不同的結束時機(end Step),讓姿態控制和色彩控制在不同階段發揮作用。Flux.1 ControlNet Union Pro(2025 年熱門)甚至把多種控制模式整合到單一模型。
IP-Adapter(Tencent-AILab 開發)讓你可以用「一張參考圖」來控制生成風格或主體一致性。不同於 LoRA 的訓練式方法,IP-Adapter 以 adapter 的方式學習圖像-文字對應,不需要重新訓練整個模型。
ReActor(基於 InsightFace)專門處理臉部替換——對一張已經生成好的圖做臉部替換,保留原本的年齡、性別、表情特徵。ComfyUI 的 ReActor 節點支援批次處理,一次替換多張圖的臉部。
值得注意的是:這些節點的更新頻率很高,與 ComfyUI v0.3.x 的相容性並非全部經過官方驗證。
3.3 ComfyUI 的 REST API:如何把工作流嵌入其他系統
ComfyUI 原生帶有一個 REST API,預設監聽 http://127.0.0.1:8188。你可以把 ComfyUI 當成一個後端服務,用 HTTP 請求驅動工作流。
import requests
stats = requests.get("http://127.0.0.1:8188/system_stats").json()
print(f"VRAM: {stats[\"vram_used\"]} / {stats[\"vram_total\"]}")這讓 ComfyUI 可以無縫嵌入任何需要 AI 圖像生成能力的系統:遊戲引擎、網頁服務、自動化腳本、即時直播疊加……
4. 效能優化:讓你的 GPU 不要再哭泣
4.1 fp16 vs fp32:模型量化節省 VRAM 的原理
fp32 的每個參數佔 4 bytes,fp16 佔 2 bytes。以 SDXL 的 UNet(約 3.5B 參數)為例:fp32 = 14 GB,fp16 = 7 GB,節省 50% VRAM,品質損失多數情況下難以肉眼察覺。
ComfyUI 的 --fp16-intermediates 參數讓中間計算結果以 fp16 儲存,而不影響模型權重本身。這可以降低記憶體峰值(peak VRAM usage)。
4.2 Batch Size / Tile 處理:大圖不一定需要大 VRAM
Tile 處理(分塊渲染)把一張大圖拆成 512×512 或 1024×1024 的小區塊,分批處理,最後拼接成完整圖像。Tile 實作通常包含一個 overlap 參數,讓每個 Tile 跟鄰居有重疊區域,用 blending 方式消除接縫。
Batch Size 是另一個維度的優化:一次生成多張圖。當模型已經載入 VRAM 後,多生成一張圖的額外成本比從頭來過低得多。ComfyUI 讓你輕鬆設定 batch size = 4、8 甚至更多。
4.3 加速採樣器:LCM、SDXL Turbo 的原理差異
LCM(Latent Consistency Models)的核心是蒸餾(distillation)。蒸餾過程僅需 4,000 訓練步(約 32 A100 GPU 小時),就能把一個原本需要 50 步的 SD 模型蒸餾成 2~8 步的 LCM 版本。LCM 的關鍵洞察是:擴散過程的ODE軌跡上存在「隱式一致性」——可以直接預測最終收斂點而不需要逐步執行每一個 step。2024 年 6 月,LCM-LoRA 的出現進一步放大了這個優勢——以 LoRA 形式訓練,可以在任何自定義 checkpoint 上使用 LCM 採樣,不需要重新蒸餾整個模型。🔶 TLCM 於 2025 年提出,但具體技術細節目前社群文件仍待補充。
SDXL Turbo(ADD,Adversarial Diffusion Distillation)結合蒸餾 + GAN 對抗訓練,確保 1~4 步的結果畫質不打折扣。ADD-XL 官方 benchmark:單步超越 LCM-XL;4 步可以打敗需要 50 步的原始 SDXL。Qualcomm 在 2025 年 1 月宣布其 Cloud AI 100 可即時執行 SDXL Turbo。
4.4 Dynamic VRAM 與 NVFP4:2026 年的最新優化
Dynamic VRAM(2026 年 2 月底正式啟用)讓 ComfyUI 能智能地在 VRAM 與系統 RAM 之間流動模型分區。官方描述這項功能能「顯著降低 RAM 佔用」,同時提升速度。🔶 不過社群也回報了部分第三方節點與 Dynamic VRAM 的相容性問題——某些節點在 Dynamic VRAM 開啟時會崩潰,目前仍在修補中。
NVFP4 量化(2026 年 1 月 8 日官方blog)是專為 NVIDIA RTX 50 系列(Blackwell 架構)設計的優化。FP4 是 4 位浮點格式,模型佔用再砍一半。RTX 5090 上使用 NVFP4 的效能提升約 2 倍(相較於 fp8 或 bf16/fp16)。⚠️ 目前 NVFP4 主要支援 Wan 2.2 等新模型,舊 SD 1.5/SDXL 模型可能不相容。
結語:為什麼值得學 ComfyUI
ComfyUI 的學習曲線比任何 GUI 都陡,但你學到的東西是可遷移的原理,而不是「這個按鈕按下去會發生什麼」的不可轉知識。
學懂了 Latent Space,你知道 VAE 在做的事情。學懂了 KSampler,你知道不同採樣器的取捨邏輯。學懂了 Custom Node,你等於打開了一扇通往整個 Stable Diffusion 生態系統的門。
節點圖不是終點,而是起點。當你能用節點思考工作流,你對 AI 圖像生成的理解就跳脫了「調參湊圖」的範疇,進入真正可以最佳化、自動化、甚至從頭設計的層次。
ComfyUI v0.3.0 在 2024 年 11 月 15 日發布,ComfyUI Desktop 在 2026 年 2 月推出——這個工具仍在快速演化。社群承認快速成長導致「非正式流程跟不上」(2026 年 3 月 27 日 Reddit 官方公告),正在重構穩定性機制。這是一件好事:代表有足夠多的人在用、在貢獻、在推著它往前。
技術細節截至 2026 年 4 月。節點生態更新快速,建議追蹤 ComfyUI 官方文件(docs.comfy.org)獲取最新資訊。